This document is no longer maintained, please check out the version information found on Kinetic Edge, at: Kafka Resource Guide.
Introduction
This is based on personal experience in supporting various clients over the use of Apache Kafka and Confluent Community Software. I have experience with Confluent Enterprise as well, but that is not directly covered in this guide.
Components
It is easy to get confused about the different licensing when it comes to its various components. Everything currently referenced in this document is free to use for developers, but some are through the Confluent Community Licenses. So, for example, if you were ever to use a Cloud hosting service for Kafka, that service (other than Confluent’s) could not leverage the Confluent Community Licensed software (version 5.1 and later).
| Component | License |
|---|---|
| Apache Kafka | Open Source, Apache 2.0 |
| Kafka Streams API | Open Source, Apache 2.0 |
| Kafka Connect 1 | Open Source, Apache 2.0 |
| Java Client | Open Source, Apache 2.0 |
| librdkafka | Open Source, Apache 2.0 |
| Schema Registry | Confluent Community License |
| Schema Registry Serdes 2 | Open Source, Apache 2.0 |
| Rest Proxy | Confluent Community License |
| ksqlDB (KSQL) | Confluent Community License |
1 While Kafka Connect is Apache 2.0 licensed, connectors may not be. Check the licensing of each connector independently.
2 The serializer and deserializers are within the same GitHub Schema Registry repository, but are licensed separately. See the LICENSE file within the subdirectories for confirmation.
Versions
Confluent Community is a release based on a specific Apache Kafka version, but bug fix releases are scheduled separately. Confluent may release bug fix release that doesn’t fully align with a bug-fix release from Apache Kafka. Please see release notes, especially if you are tracking down a specific issue you need fixed.
To make this easier, I maintain a table of library dependencies along with tracking versions with some notation on their differences: Apache Kafka, Confluent Community.
Current Version
As of 3/31/2022, Apache Kafka is at 3.1.0 and Confluent’s Community Edition is at 7.1.0 (based on Apache Kafka 3.1.0). Confluent’s release may have bug-fixes prior to Apache Kafka providing a .X bug-fix release. I highly recommend looking at each release-notes to verify if an issue is fixed in the version you are using (or plan to use).
With Kafka 3.0 being a major release, breaking changes were made. This includes client changes, such as making acks=all the default for production. If you upgrade your client library to 3.x but using an older cluster, you need to be aware of what happens in the broker vs what happens in the client.
Terminology / Key Components
Below, I summarize core concepts and terminology. If you are exploring Apache Kafka material for your development or operational team, I recommend knowing these basic terms, as it will help you when reviewing training material. I also highly recommend reading through Confluent’s introduction material.
I approach terminology in order of composition. For example, a key is part of a message, so I define key before I define message. This does not work perfectly, as it is best to describe out of order; so consider reading through this multiple times.
I am eager to improve documentation to make it easier for others to understand; I welcome feedback.
Key
The key is usually how a partition is selected. You can do custom partitioning, but you can easily break streams that rely upon having multiple topics (with the same number of partitions) be in the same partition number. If your message does not have a key (it is set to null) it will be randomly assigned a partition (by the producer client library). To a Kafka broker, a key is just an array of bytes.
Value
The value is usually the heart of the message. There are many serializers and deserializers out there to help get your message into Kafka; to the Kafka Brokers it is just an array of bytes.
Message
A message is the event that is written to Kafka. A message is a key, value, timestamp, and optional headers. Consider this information as atomic and immutable.
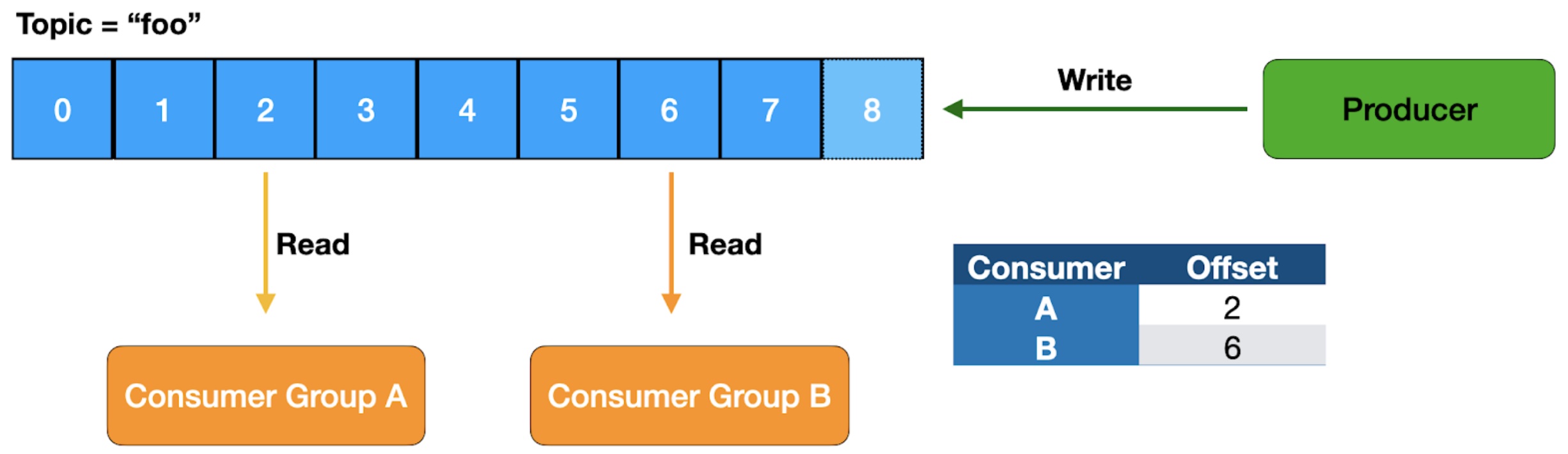
Offset
The offset is an ever-increasing number with for a given partition. Given a topic, partition, and offset, you always reference the same message in the broker. Now, if a topic is compacted (more advanced concept), the message may no longer be available, but it would never reference something different from what it originally was.
Partition
A partition is the physical unit that the producer writes and the consumer reads. A topic is configured to have 1 or more partitions. The point of having multiple partitions is to increase throughput and allow Kafka to scale.
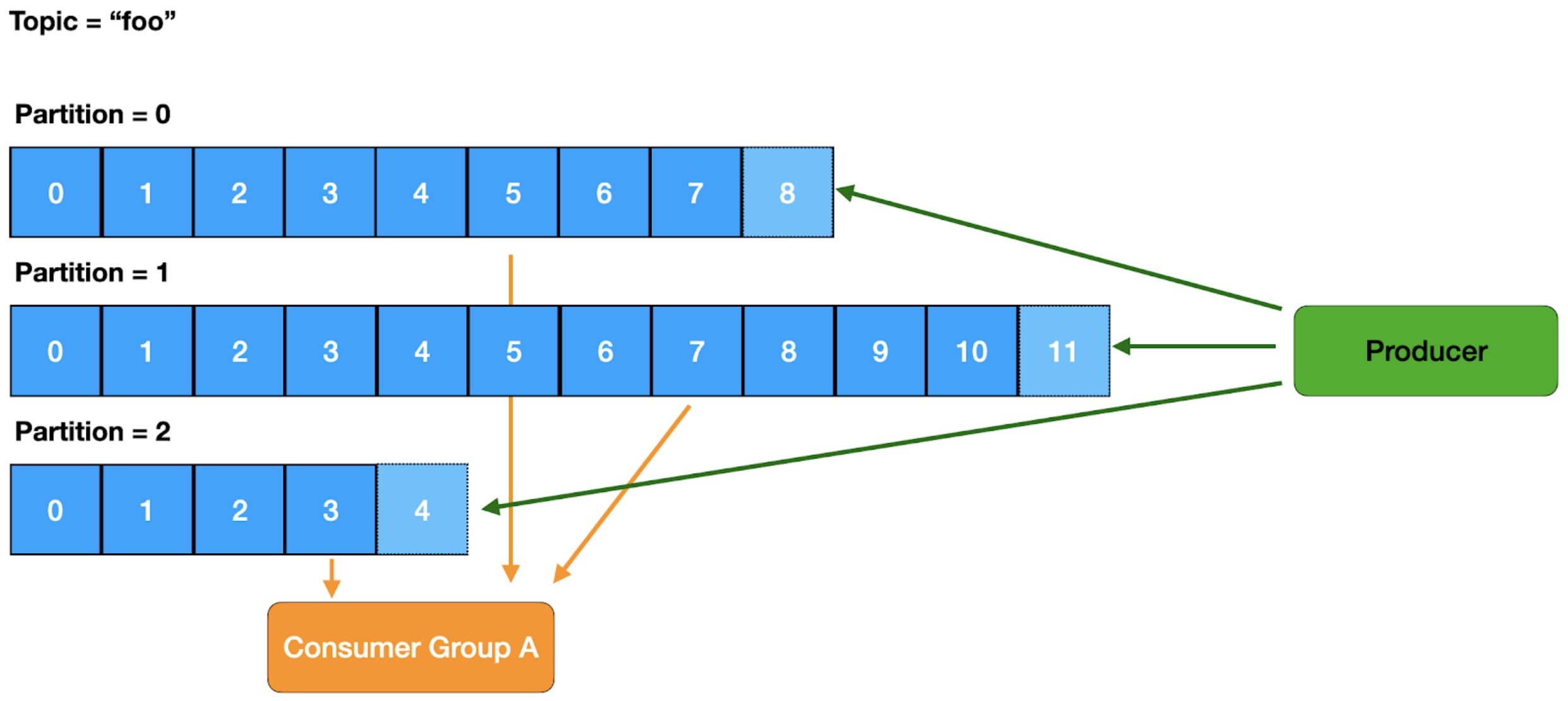
Topic
A topic is the logical unit that a producer writes to and a consumer reads from. A topic is a set of partitions and set of messages in those partitions where the key (if provided) keeps messages of the same key in the same partition (to achieve loose ordering).
Replication Factor
The number of copies to be made of a topic for reliability and durability. Replication factor is configured at the topic level, but implemented at the partition level. The number of replications is limited by the number of brokers, as a replication is never placed on the same broker as another replica.
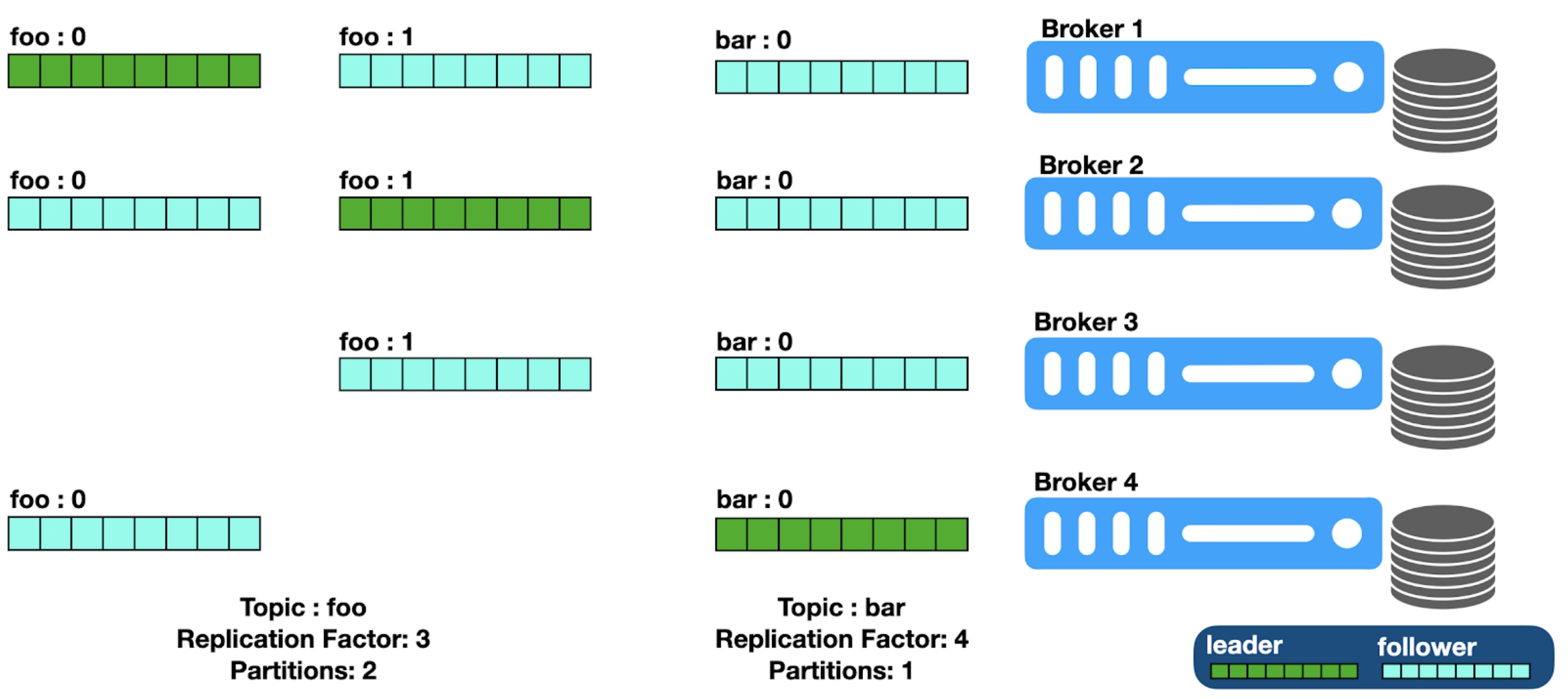
Broker
The Kafka Broker is the heart of Kafka. It is where all things start when it comes to Kafka. Multiple brokers exist so work is distributed (performance) and replicated (reliability) among them. Each partition of a topic can have a different broker be the leader.
Producer
The producer is the publisher of the message to the Kafka Broker. The logic of knowing what broker to communicate to for a given message is handled by the client. It communicates directly with the broker that is the leader for that given partition.
Consumer Group
The unique identifier used to allow for multiple instances of a consumer to work together.
Consumer
The consumer is who receives the message. Consumers typically read from a partition of the topic from the broker that is the leader, but there are options to configure this. Consumers work together within a consumer group to allow work to be distributed. Partitions are not split between consumers, so the maximum number of active consumers is limited by the number of partitions of the topic.
Training Material
There is a lot of material out there to learn Apache Kafka. Here are the resources I have personally explored at various levels. For example, I have done the on-demand training for Kafka Development and the in-person (virtual) training of Confluent Operations. While I cannot say I have explored every version of each offering, I have attended them. This includes all the Udemy courses I reference as well.
Confluent
Confluent offers instructor-led and self-paced training. See https://www.confluent.io/training for details.
Instructor Lead
The instructor lead course is a 3-day course. The operational course I attended was online, and everyone was free to discuss and ask questions throughout the course. The instructor was well versed in the subject, and having the ability to have in-depth questions answered throughout the training was beneficial.
Self Paced
The Self Paced development course provides the same material as the instructor-led course. The benefit allowed me to watch the material at my pace during non-business hours. Tim Berglund hosted the Developer course and does an excellent job presenting (as always) the material.
The training material is well done. If you are to go down this path of taking any of the Confluent courses, I recommend the following:
- Have developers take the same course so they can continue with discussions even during a break.
- Make sure your team is committed to this instruction. I know of those taking the online versions just watching the video and not doing the coursework. These courses are best when the instructional material is fully utilized, and do not let your team undermine their value.
- Ask the instructor questions. If the instructor does not know the answer, they reach out during breaks to others to get those answers addressed.
Developer Tutorials and Examples
Confluent provides plenty of examples, and you should check them out.
https://developer.confluent.io
https://kafka-tutorials.confluent.io
Confluent Platform Demo
https://docs.confluent.io/current/tutorials/cp-demo/docs/index.html
Confluent Referenced Examples
https://github.com/confluentinc/examples
Confluent Community Slack
The slack community confluentcommunity.slack.com is an excellent resource for learning Kafka. Consider slack the area you go to if you want to have a conversation.
Confluent Community Forum
The community forum https://forum.confluent.io was created to provide a searchable archive, which is not available from Slack. Slack is used for interactive questions and the forum seems to be used where answers and solutions are to be searchable. Personally, I enjoy the more interactive nature of Slack and can lead to some good discussions. For finding answers and/or to ensure that the questions and answers can help others, the forum is the place to go.
Udemy
There are many courses available on Udemy for a very reasonable price, provided you have a coupon code. You should never spend more than $20. Start at https://www.udemy.com/topic/apache-kafka.
I strongly recommend Stéphane Maarek’s courses. Wait for a sale (they happen frequently) or find a discount code before purchasing. Once you have one course from Stephane Maarek, you are provided a discount code to use for the other courses. Currently, the courses go between $10 to $15 when a promotion or discount is available.
I switch between my iPad and computer to watch these courses. I have found I watched most at speed 1.25 and many segments at 1.5 or 1.75. It depends on my familiarity with the content and if it is a lecture or an exercise. Personally, I would dedicate watching it at a faster speed than trying to multitask while watching it.
Learn Apache Kafka for Beginners v3
https://www.udemy.com/apache-kafka
- Version 3 Review
Version 3 of this course was released in March, 2022. In addition to refreshing to the latest version of Apache Kafka, it also has some example changes. I have yet to watch v3 of this content and will audit it soon. The nice thing about Udemy courses is it allows for Authors to refresh courses. I don’t have to buy a new version, but rather get it as part of my original purchase.
- Version 2 Review
This is an excellent first course for Apache Kafka.
Even if you are familiar with the fundamentals of producing and consuming, still consider taking this course. The topics on throughput and idempotency are very well done. Sections 62, 63, & 64 and is the best discussion of producer idempotency I have seen. Stephané also provides annex material that he has added over time to enrich the course. The course was refreshed to Apache Kafka 2.0 in 2018.
It is easy to watch Section 13 without pausing and thinking through the use-cases before Stéphane provides his overview. I strongly recommend taking the time to come up with your architecture overview before you watch it.
This has a few dated commands, including the above mentioned --zookeeper command line switch. Replace kafka-topics --zookeeper zookeeper:2181 --list with kafka-topics --bootstrap-server broker-1:9092 --list.
Kafka Streams for Data Processing
https://www.udemy.com/kafka-streams
I highly recommend this for developers who are working with Kafka Streams. You should have completed the beginner course, the Confluent Developer Training course, or have experience with Apache Kafka producers and consumers.
This course focuses on the stream DSL. If you want to learn about the raw topology processors, this is not for you. Personally, I think it is better to learn the DSL before considering the processor API. If you need to leverage the processor API, having experience with the DSL will help you do that more effectively.
Confluent Schema Registry and Rest Proxy
https://www.udemy.com/confluent-schema-registry
If you are new to Avro, you could benefit from this course. However, this course isn’t at the level of the others. I do like how it explains the schema registry and how it avoids putting the Avro schema on the message and leverages the schema registry, but you don’t need to know those details right away, and when you do, you can research it. I recommend this course to clients, as the need for data governance and a schema registry is important to building enterprise systems.
Kafka Connect Hands-on Learning
https://www.udemy.com/course/kafka-connect
My original thought on this course was to avoid it. However, the more I think about it, the course gives excellent foundations to the schema registry. I needed to rethink this course as though I did not know about connectors, connector-cluster, or writing a connector. If you are working with connectors and are new to them, take this course.
Kafka Monitoring and Operations
https://www.udemy.com/kafka-monitoring-and-operations
Even though I had already use Prometheus and Grafana with my docker clusters, this was a great course. It is also presented using AWS, which is an excellent reminder of some AWS concepts. While it is instructed w/out fully leveraging the free tier, I was able to do all of the instructional exercises using AWS free-tier resources.
I plan on watching this course again to pull out some of the concepts he addresses, so I have references to them and can use them for consideration at a client.
Kafka Cluster Setup and Administration
https://www.udemy.com/kafka-cluster-setup
This is my favorite course. It uses AWS, and I was able to do all of the exercises using the free-tier. Again, it is a course I want to watch again to leverage and reference material from this course for clients. Even if you are a developer and do not want to be part of Operations, consider taking this course. Also, having an overview of operations improves your Kafka development skills.
Kafka Security (SSL SASL Kerberos ACL)
https://www.udemy.com/apache-kafka-security
If you ever need to set up a Kafka Cluster with security, I would highly recommend this course. Developers do not need to take this course. I found this course very helpful with Kafka and Kerberos.
Apache Kafka Series - KSQL for Stream Processing - Hands-On!
https://www.udemy.com/kafka-ksql
An excellent introduction to ksqlDB. I do not see this course as a needed course by developers who are familiar with Kafka Streams. However, if you are not doing Kafka Streams and want exposure to stream processing and be able to take advantage of it, then I would recommend taking this course.
Kafkademy
Stéphane Maarek and the rest of the team at Conduktor also has a great introduction to Apache Kafka.
What I really enjoy about the hands-on information it provides, like what it gives you in the CLI Tutorials.
Resources
Books
The following books are excellent resources, and Confluent provides free online copies of those books and the books linked to those resources.
The Kafka Definitive Guide
The Kafka Definitive Guide, 2nd Edition, Gwen Shapira, Todd Palino, Rajini Sivaram & Krit Petty; first edition (The Kafka Definitive Guide, Neha Narkhede, Gwen Shapira & Todd Palino).
When it comes to reference guides, pairing this with the Apache Kafka documentation will really help you with your journey.
Kafka In Action
https://www.manning.com/books/kafka-in-action
This is a recently released book. I will add my thoughts after I read it.
Kafka Streams in Action 2nd Edition
https://www.manning.com/books/kafka-streams-in-action-second-edition, William P. Bejeck Jr.
I have the MEAP of the 2nd edition and really enjoy the details that Bill goes into and the examples provided. Bill also shows great desire and care around data governance; which is super important. If you want to get a good foundation around data modeling in a streaming world; I highly recommend reading this book.
Bill has actively contributed to the Apache Kafka project over the past 6 years. I have seen him validate and interrogate the source code to validate changes to Kafka Streams; enjoy seeing the attention to detail within his craft.
Mastering Kafka Streams and ksqlDB
https://www.confluent.io/thank-you/ebook/mastering-kafka-streams-and-ksqldb, Mitch Seymour
I highly recommend chapter 5. The example used for windowing and time is refreshing. It is a nice use-case and a great way to get introduction into window processing.
Kafka Streams is built for window processing; and what better way to learn more about it than from this book.
Designing Event-Driven Systems
Designing Event-Driven Systems, Ben Stopford
This is a must-read book, even if you do not use Apache Kafka. It is about designing event-driven systems and uses Apache Kafka as the technology that allows for systems to be built this way.
“Beyond that, streaming encourages services to retain control, particularly of their data, rather than providing orchestration from a single, central team or platform.” (page 14)
Chapter 5 discusses using events for notification, and using events to provide state transfer is an excellent example of what this book offers.
Chapter 11 has an excellent discussion of the single writer principle and a variation of the single writer per transaction.
Making Sense of Stream Processing
Making Sense of Stream Processing, Martin Kleppmann
Kleppmann is an excellent resource for understanding distributed systems, and concepts of concurrent processing, and transactions. If you are wanting to learn the specifics of Apache Kafka, the other books and resources are more for you. For being a strong architect and understanding how how to piece things together; do check out this book.
Apache Kafka Transaction Data Streaming for Dummies
Apache Kafka Transaction Data Streaming for Dummies, by Thornton J. Craig, Kevin Petrie, Tim Berglund
Change Data Capture (CDC) is an integral part of leveraging Apache Kafka with legacy systems. Check out chapters 3 and 4 to figure out how CDC works for you and your enterprise needs. This is a small book and some nice call-outs about CDC, something that is a big piece most enterprise clients.
Gently Down the Stream
Gently Down the Stream, Mitch Seymour
This book was writtent to explain Kafka to children, but it a great introduction book for anyone. Give this a great book and great introduction to Apache Kafka.
Blogs
The confluent blogs, https://www.confluent.io/blog, are beneficial. Once you have a little bit of familiarity with Kafka, it is the easiest way to find additional material to inject and improve your understanding of Kafka.
Putting Apache Kafka To Use
This is an excellent overview of Kafka by Jay Kreps. Part one is a relatively simple overview and should be a quick read. Part 2 goes into some design considerations. It also gives an excellent reason to consider Avro but points out that consistency is key (at least it is worth reading to understand that). Included is also his talk on the use of Avro. There are other links (especially at the end of part 1) that are worth exploring.
- https://www.confluent.io/blog/stream-data-platform-1
- https://www.confluent.io/blog/stream-data-platform-2
- https://www.confluent.io/blog/avro-kafka-data
Building a Microservices Ecosystem with Kafka Streams and KSQL
This blog covers a lot of what Ben covered in his book. It also gives a working example. It is a great use-case for interactive queries of Kafka Streams. Shortcomings of Kafka Streams and leveraging interactive queries are no longer a major issue as well, thanks to these Kafka improvement proposals: KIP-535 - Allow Allow state stores to serve stale reads during rebalance and KIP-429: Kafka Consumer Incremental Rebalance Protocol.
The code from the above blog and other examples from Confluent can be found in their Kafka Streams Examples repository.
Event Sourcing
- https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection
- https://www.confluent.io/blog/event-sourcing-using-apache-kafka
- https://www.confluent.io/blog/event-sourcing-vs-derivative-event-sourcing-explained
Operations & Performance
The graphic on end-to-end latency is the best out there. Also, understanding that acks=0, acks=1, and acks=ALL has no impact on end-to-end latency (it just impacts when the producer knows the message has been accepted into Kafka)
Meetups
The Apache Kafka Meetups that are administered by Confluent are all virtual and recorded since March 2020. You can access those materials on-line and see past events as well as upcoming events. To attend a virtual event, you do need to register to get access to the zoom link, as they are password protected.
Podcasts
This Confluent podcast “Streaming Audio: a Confluent podcast about Apache Kafka” is fantastic. There are not too many programming-related podcasts I find valuable; great content to listen to during a commute.
Videos
Confluent Youtube Channel
Confluent puts all of their videos on this channel, recently Streaming Audio has a video version available here as wel.
Kafka Summit
Apache Kafka now has a link to the highest-rated presentations from Kafka Summit 2018 and later, and it separates the links by classification.
If you are wanting to look at the content of a given Summit, search “kafka summit” at https://www.confluent.io/resources. You should be able to quickly get to the summit of interest. This link can be used to search for the eBooks, white-papers, and more.
Specific Videos
How Does Kafka Work
A short introduction. This 10-minute video will give you an excellent overview of the core concept of an Apache Kafka Cluster from Jay Kreps, Confluent (Confluent founder & co-creator of Kafka while at Linked-In)
- How Does Kafka Work. March 1st, 2016; Jay Kreps
What is Apache Kafka®?
A nice 10+ minute introduction.
- What is Apache Kafka?. October 30th, 2019; Tim Berglund
Events, Dear Boy, Events
A excellent talk on thinking about events and how things change.
- Events, Dear Boy, Events. JFocus February 16th, 2020; Tim Berglund, Confluent
Consumer Group Rebalance Protocol
This is just a great talk – again this is a rather special area of Kafka, but it is eye-opening to what is going on within the client layer.
- The Magical Rebalance Protocol of Apache Kafka. Strange Loop; October 16th, 2018; Gwen Shapira, Confluent
Choose Your Own Topology, A Kafka Streams Adventure
This is an excellent talk for understanding Kafka Streams and when to use various technologies.
- Choose Your Own Topology, A Kafka Streams Adventure. JFocus; February 16th, 2020; Anna McDonald, Confluent
Processing Streaming Data with KSQL
Even if you do not plan to use ksqlDB, it is great level of abstraction to work with eventing w/out having to do a lot of coding. Also, the SQL-like syntax is perfect for presentations on stream processing as it minimizes the coding and maximizes the focus on the business logic and problem domain.
- Processing Streaming Data with KSQL. GOTO 2019; November 28th, 2019; Tim Berglund, Confluent
Exactly Once Semantics
Transactions in a distributed system are quite difficult to achieve. This presentation is a must if you want to start ot unravel how EOS is built within Kafka.
- EOS in Kafka: Listen Up I Will Only Say This Once! Strange Loop; September 30th, 2017; Jason Gustafson, Confluent
Also, checkout this excellent article by Andy Bryant – multiple points of view is a must to grok Kafka’s exactly-one semantics. Processing Guarentees in Kafka.
Kafka Streams: What’s the time? …and why? and The Flux Capacitor of Kafka Streams and ksqlDB
When it comes to understanding Kafka Streams, Windows, State you need to search fo talks by Matthias Sax. And you should start with these.
What’s the time? …and why?. Kafka Summit, 2019; Matthias Sax, Confluent
The Flux Capacitor of Kafka Streams and ksqlDB. Kafka Summit, 2020; Matthais Sax, Confluent
Using Kafka to Discover Events Hidden in your Database
This is a great talk. It really shows so much about streaming events in a use-case that fix so many enterprise customers I have talked to about Apache Kafka.
Using Kafka to Discover Events Hidden in your Database. Kafka Summit, 2019; Anna McDonald, SAS (now at Confluent)
Source Code
Have the source-code downloaded and ready to explore. I find it of great value when someone is unsure of my recommendations. For example, I almost always recommend setting retries to max-integer. I then show the default producer settings used by the Apache Kafka Connect API, which does the same thing. T he settings and comments within the code is a great reference to see a set of properties configured as a logical unit.
Closing Thoughts - My Personal Words Of Advice
Kafka Is Constantly Evolving
Have quick access to 2 versions of Kafka Documentation:
- The version of Kafka that your training material is using
- The version of Kafka that you have installed for your development.
As you look at training material, keep in mind the version of Apache Kafka at the time the material was written.
There have been a lot of changes over the years.
For example, Apache Kafka used to require tools to access zookeeper directly.
If you see documentation or presentations showing --zookeeper <zookeeper>:2181 for using a command-line utility, it is most likely replaced with --bootstrap-server <broker>:9092.
If you see issues between instruction and using the command line tools, compare the documentation of the version you are using with the documentation of Apache Kafka at the time the material was created.
Installation
There are two installations you need to think about.
- Installation for developers.
- Production (and production-like) installation.
Developer Installation
Ideally, developers should have their own local installation. This is best leverage through a docker/container based installation. If that is not available, a confluent community local installation is also available. While using cloud resources (managed or self-hosted) are options, it is more difficult for developers to try things out independently and also there is unexpected costs.
My recommendation is to install the Confluent Community Edition on your development machine, which can be found here: Confluent Download. I use this to make the command line tools available within my development environment. Then install a container based solution. Confluent’s images are great for such an environment, and my spin on using them can be found here: kafka-local. In addition to the Kafka Cluster compose file, there are ones for Kafka Connect, ksqlDB, MySQL, Apache Druid, and more. It would be my recommendation to build your own ecosystem using mine (or someone else’s) as a guide. Make it your own, since you may spend a lot of time using it.
I would check out Confluent’s repository of containers: Kafka Images, Schema Registry Images, and ksqlDB Images. Pulling the images from Docker doesn’t require any use or knowledge of these repositories. However, you may want to search GitHub for other uses of these containers to find a setup you might like better than mine. Some like a single docker-compose file, but I like having the ability to start and stop just the various components I need for development.
Production Installation
The recommendation for production installation is out of scope for this documentation, as there are so many variables to consider. Check out service offerings as well as self-managed installations. For self-managed installations, be sure you are planning to train and/or hire for managing Kafka operations.
Docker
Docker makes it easy to run multiple brokers on your development machine and why I encourage it over running it locally. It also makes it possible to run on a Windows machine (provided Hypervisor is available and you can run Docker).
Because I like to showcase replication and how clients talk to each broker directly, I configure a three broker cluster for development. While one broker is ok for learning Kafka, having three brokers provides a minimal configuration that still showcases the distributed nature of Apache Kafka.
The amount of services needed to run Kafka is relatively large. The default Docker settings may not be sufficient. Minimal settings should probably be 4 CPUs, 6GB memory, and a swap of 1GB. If you have a laptop with 32GB of memory, consider settings 8 CPUs, 12GB memory and a swap of 1 or 2GB. In either case using a docker disk of 64GB is probably sufficient. If you are close to running out of space, you probably want to prune images anyway, as it is likely you have unused layers taking up disk space.
Docker Container
When using a docker container, it is essential to understand how broker addressing works and how docker port mapping works. Clients running on your machine hosting the docker container and clients running within docker access the brokers differently (at least on a Mac). The way to allow for the hostname resolving to work is to have two advertised listeners for the brokers. This allows your application on your laptop to use localhost and the application within the containers to use the hostname.
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
Spring Boot
The best way to set up a spring boot application is to utilize the SpringBoot application builder at https://start.spring.io. Construct the desired build system (maven or gradle), Spring Boot version, and the selected components. For Kafka, adding in Kafka and Kafka Streams would be the ones to add, and then consider adding in Cloud Stream if you want to take advantage of the Spring Cloud additions.
Keep in mind you can leverage the kafka-clients library directly from Spring; leveraging the spring libraries that integrate Kafka within the Spring ecosystem are not required. If you are working through various tutorials and want to integrate those concepts into your frameworks; do so without leveraging the framework libraries, as it is best to understand Kafka w/out those libraries (in my opinion).
Gradle
If you prefer Gradle over Maven use https://start.spring.io to set up the scaffolding for your project.
When it comes to Avro and SpecificRecord (generating java code from the Avro source files), the Gradle plugin works better for me than Maven’s plugin. In Maven I had to manage compile order between specifications, and with Gradle plugin I did not. Also, the Gradle plugin has done a great job staying current. Just be sure to check release notes and make sure you use the plugin compatible with the Avro version you are using.
Security
Security is a task in of itself with tons of nuances. Hortonworks has a nice section on security. I recommend finding examples that mimic closely to the type of setting you are needed. Here is one I have built around using Kafka with SSL client side authentication, kafka-ssl-cluster. It is stuff rough around the edges, I am working on more open-source examples.
Kafka Connect
Kafka Connect is a framework for building sources (producers) to bring data into Kafka and sinks (consumers) to pull data from Kafka. It handles the distribution of tasks and utilizes configuration and RESTful endpoints to configure and maintain those workers. Do not overlook leveraging Kafka Connect.
Kafka Streams
Kafka Streams is a Java library that leverages Kafka Consumer and Producer APIs for building a stateful way of processing data. It has a state store for providing state. Kafka Streams is a topology graph that can be built with some very low-level APIs but is usually constructed with the Streams DSL. ksqlDB is a version of KafkaStreams that provides an even higher level language on top of the DSL.
If you are doing stateful processing, you should explore the use of Kafka Streams. If you already use Spark, Flink, or other stateful processing engines then work with those teams to understand what makes sense to keep on those servers, and see how Kafka Streams could still help you.
ksqlDB
ksqlDB is an application that provides a level of abstraction on top of a Kafka Streams application.
In November 2019, it was released as its own project at https://ksqldb.io, and is now referred to ksqlDB (it was just ksql prior to that time).
It handles the distribution of tasks between kafka streams deployed to do ksql tasks.
KSQL tasks are SQL-like syntax of creating Kafka Stream topologies.
In addition to building stream topologies through KSQL, interactive queries of state stores are not available through the same KSQL syntax.
While released as part of the Confluent Platform, it has its own releases as well, as of 2/27/2022, 0.21.0 is the latest release.
Check for tags of the following format vX.YY.X-ksqldb within the repository to find the community tagged versions.
Avro and the Schema Registry
As of Confluent 5.5, the Schema Registry now supports JSON and Protobuf, in addition to Avro,
https://www.confluent.io/blog/confluent-platform-now-supports-protobuf-json-schema-custom-formats.
The confluent open-source Avro serializer and deserializer are designed around having a schema registry. The schema registry allows the Avro data to be put on the Kafka topic without the need to serialize the Schema with it. The Schema is to Avro as XSD is to XML, but where an XML file can be parsed without the XSD, that is not the case with Avro. Avro is strongly typed, and the Schema enforces it.
When serializing Avro, there is a concept of a specific Avro record and a generic Avro record. These are Avro concepts leveraged by the Serializer/Deserializer. When comparing Avro to JSON, Generic Avro is like JsonNode, and Specific Avro is like a Java POJO with Jackson annotations.
Avro has a concept of forward, backward, and full.
If you are exploring Avro, you will need the schema registry. As you change versions of a given Avro bean, you may run into the schema registry complaining about incompatible versions. The best thing to do here is to disable compatibility checks. Do not disable compatibility checks in production.
curl -X PUT http://localhost:8081/config -d '{"compatibility": "NONE"}' -H "Content-Type:application/json"
Use GitHub Searching to find examples
When I am trying to figure out how to configure something I don’t search with Google; I search on GitHub (and select Code after doing my search).
Curious on how to use the RegexRouter?
extension:json org.apache.kafka.connect.transforms.RegexRouter
Interested in installing connectors within a docker compose file?
filename:docker-compose.yml kafka confluent-hub
Kafka Local
As I mentioned earlier, I use this ecosystem for all of my local development. I find this environment critical for understanding and development against Kafka.
- I can have a local environment with 3 brokers.
- I can start/stop various additional components independently of each other.
- A simple
docker compose down -vallows me to start with a clean installation. - A setup that allows me to run application within a container or from my laptop.
https://github.com/nbuesing/kafka-local
Reach Out
If you are interested in knowing more about this or anything I have shared, would be happy to have a conversation with you.