Kafka Summit London 2022 had tons of great content, an excellent venue, and a well-organized event. Soon the event’s content will be available on-demand; with 4 concurrent tracks, even those that attended will enjoy having that.
Here are the sessions I attended and a brief introduction; hoping you are excited to watch them when the on-demand content is available. I know I have just as many sessions left to watch on-demand as I watched in person. I will update this with links to sessions and sessions I watch on-demand.
Sessions
Day 1
“Streaming Updates through Complex Operations in Kafka Streams at Scale”
Victor Künstler, Software Engineer, bakdata GmbH
As a Kafka Streams developer, I was glad to be able this talk fit my schedule. Tons of great information on building streaming applications and making sure they scale. If you are building Kafka Streams applications and are looking for advice when you need to scale check out this presentation. Even if you are just getting started in your Kafka Streams journey, there is material here for you.
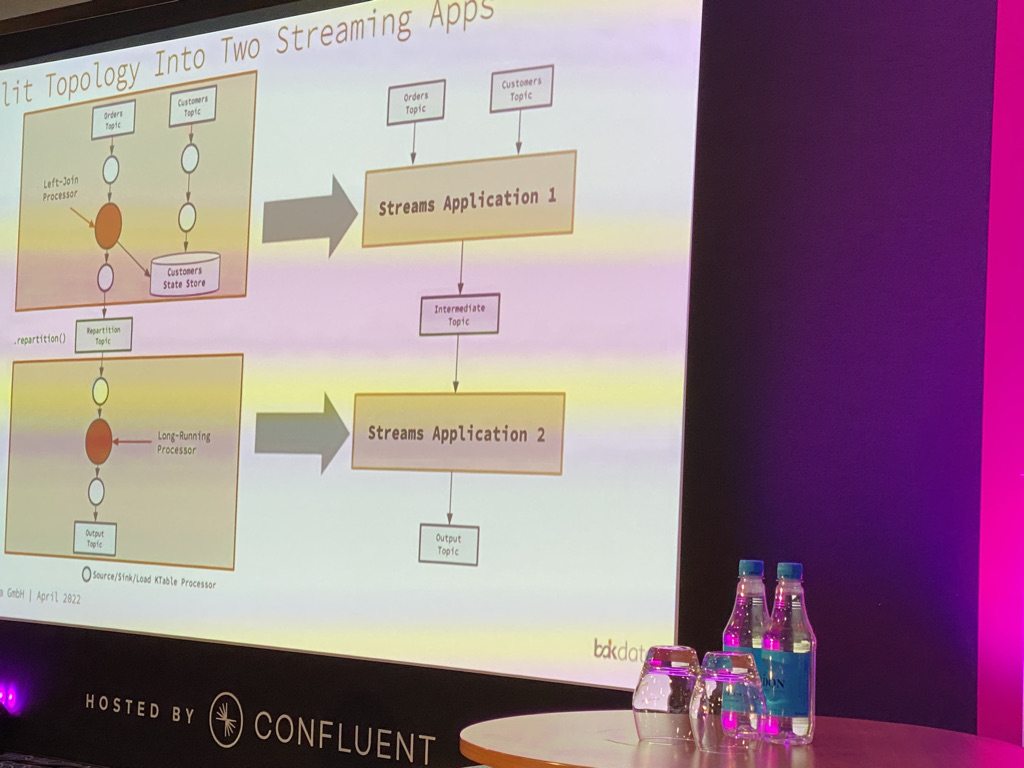
“Geo-replicated Kafka Streams Apps”
Ryanne Dolan, Senior Staff SWE, LinkedIn
Providing techniques to allow for Kafka Streams application to work in a multi-cluster way is important. Multi-cluster Kafka deployments with fan-out techniques is one of the useful topics discussed.

“Know Your Topics – A Deep Dive on Topic IDs with KIP-516”
Justine Olshan, Backend Software Engineer, Confluent
There is more here than just learning about KIP-516 and its benefits to Apache Kafka. Seeing the level of work needed to make a change that breaks API. Something very challenging in distributed systems that require upgrading w/out downtime. Great first-hand experience showcasing the process. Not only do you learn about the destination; you experience the process to get there.

“Using Modular Topologies in Kafka Streams to Scale ksql’s Persistent Queries”
Walker Carlson, Software Engineer, Confluent and A. Sophie Blee-Goldman, Senior Software Engineer, Confluent
The improvements to ksqlDB to handle additional queries are fantastic. It is a great engineering discussion to showcase the work being done to make ksqlDB scale and support dynamic queries. The customizations of Kafka Streams to support dynamic topologies are great. I hope these customizations lead to KIPs (Kafka Improvement Proposals) and become part of Apache Kafka.

“Increasing Kafka Connect Throughput”
Catalin Pop, Staff Technical Support Engineer, Confluent
Do you want to see the importance of understanding your configuration? An example of doubling the throughput of a JDBC Source connector by measuring, understanding the configurations, calculating needed values, and finally applying the changes. For someone that works with clients that need to understand the various components of Kafka; having material like this makes my job easier.

Day 2
“Practical Pipelines: A Houseplant Soil Alerting System with ksqlDB”
Danica Fine, Senior Developer Advocate, Confluent
Solid content in an end-to-end project showing data collection, data transformation, and notification. A great balance on hardware, pipelines, ksqlDB, and integration. Seeing python on a Raspberry Pi to publish messages directly to Kafka hosted on Confluent Cloud is great. Who doesn’t want to see soldering and a breadboard?

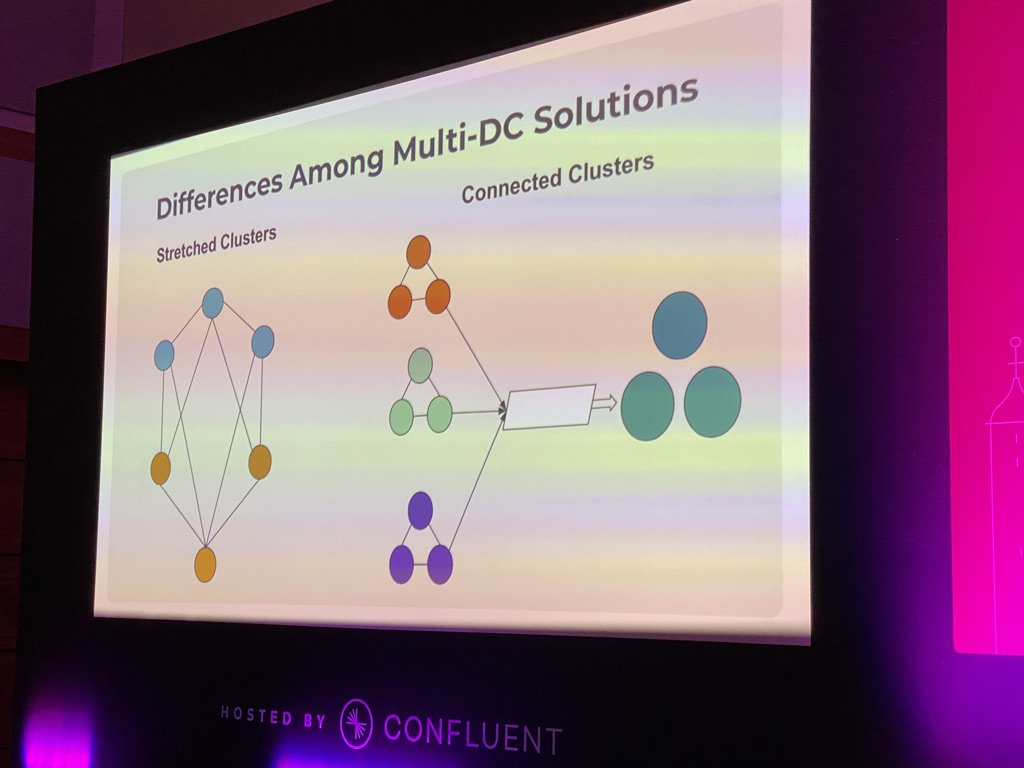
“A Hitchhiker’s Guide to Apache Kafka Geo-Replication”
Sanjana Kaundinya, Software Engineer, Confluent and Rajini Sivaram, Principal Engineer, Confluent
Understanding multi-data center solutions is critical to set up enterprise solution that can scale and are meet SLA requirements. Great insight into stretch clusters, connected clusters, and data replication. I now have additional colleagues I can reach out to when I need to learn more.
“Bringing Kafka Without Zookeeper Into Production”
Colin McCabe, Principal Engineer, Confluent
The replacement of Zookeeper with KRaft is fascinating. Seeing the process for a rolling replacement from Zookeeper to KRaft is impressive and is so insightful. Start understanding this now, so it will be easier to see and plan for the migration to KRaft for your own organizations.

“Disaster Recovery Options Running Apache Kafka in Kubernetes”
Rema Subramanian, Customer Success Technical Architect, Confluent and Jennifer Snipes, Staff Customer Success Technical Architect, Confluent
I am not a Kubernetes expert. This provides great insights into the running Apache Kafka on Kubernetes. Seeing the different nuances around DR when leveraging Kubernetes is great material for many organizations running their own Apache Kafka clusters.

“Improving Fault Tolerance and Scaling Out in Kafka Streams”
Bill Bejeck, DevX, Confluent
The key to understanding the scaling of Kafka Streams is to understand consumer groups, stream threading, and task execution. All of that is available here. Great content which is very concise and easy to understand.

“Developing Kafka Streams Applications with Upgradability in Mind”
Neil Buesing, Principal Solutions Architect, Rill Data
I had a blast.

On Demand
When content becomes available on-demand, I’ll be watching more — I hope you do too!
I am going to update this as I see more.